
Plus de 800 fiches pratiques pour les managers, sans pub et sans traceurs…

- ▶ Management de l'entreprise ▶ Management Démocratique
- Conception de la stratégie
- Principes de gouvernance
- La Performance des métier
- Le contrôle de gestion
- ▶ Innover en équipe
- L'Innovation et la Performance
- L'Innovation Managériale
- La Méthode SOCRIDE
- ▶ Décider au quotidien
- Le processus de Décision
- La Décision en équipe
- Les Techniques de décision
- ▶ Guide gratuit de l'Autoformation
- Méthode d'autoformation
- Les 7 Qualités pour réussir
- Comment s'auto-évaluer ?
- ▶ Formation Gratuite Management
- Formation tableau de bord et BI
- Formation Management de Projet
- Formation Entrepreneuriat
- ▶ ebook et PDF management gratuits
- ▶ PDF Entrepreneuriat
- ▶ ebook Perfonomique


 PDF
PDF

Qu'est-ce que le Text Mining ?
Extraire le sens des documents non structurés

Définition du Text Mining
Le Text Mining est un ensemble de méthodes, de techniques et d'outils pour exploiter les documents non structurés que sont les textes écrits, comme les fichiers bureautiques de type Word ®, les emails, les documents de présentation de type Powerpoint ®...Pour extraire du sens de documents non structurés, le text mining s'appuie sur des techniques d'analyse linguistique. Le text mining est utilisé pour classer des documents, réaliser des résumés de synthèse automatique ou encore pour assister la veille stratégique ou technologique selon des pistes de recherches prédéfinies.
Le Text Mining est (quasi) aussi ancien que l'informatique
Pour l'anecdote, l'utilisation de l'informatique pour automatiser la synthèse de textes n'est vraiment pas récente. Hans Peter Luhn, chercheur chez IBM, le véritable inventeur du terme de Business Intelligence en 1958, donc bien avant Howard Dresner, publiait en 1957 une étude intitulée "The Automatic Creation of Literature Abstracts". Cette passionnante étude est accessible directement sur le site de recherche IBM.
Pour la petite histoire, l'IBM 704 sorti en 1955 a marqué son époque. C'est notamment sur cette machine qu'a été développé le langage Fortran. Voir ici IBM 704 sur la wikipedia. Nous sommes donc bien au tout début de l'essor des applications informatisées.
Et aujourd'hui ?
Eh bien aujourd'hui, Google propose le même "service", si on peut le dénommer ainsi, mais à grande échelle. En effet, un brevet déposé par le leader incontesté (pour le moment) de la recherche sur le web ne cache pas ses ambitions. Google se propose en effet de créer du contenu "original" en synthétisant les articles lus sur le web. En automatique bien entendu.
Algorithmes
Un premier algorithme extrait la substantifique moelle d'un article, c'est dire le résumé-synthèse mentionné ci-dessus, l'extractive summaries en jargon google. Il répète la même opération pour d'autres articles complémentaires traitant du même sujet.Puis un second algorithme, "Abstractive Summaries", construit une synthèse globale écrite à sa façon, en paraphrasant les textes originaux. Avec cette future fonction, Google sera en mesure de répondre à une question d'un internaute directement sans faire appel à une recherche sur le web (featured snippets). Ensuite, toujours selon l'article en référence ci-dessous, Google se propose de bâtir en automatique une "Wikipédia maison".
Cela dit comparativement au nombre quasi incommensurable d'articles de la Wikipédia, anglophone notamment, écrits par des robots, on ne sera pas surpris par cette future "encyclopédie".
 La ressource originale : le texte de la revue en ligne Searchenginejournal : Google’s New Algorithm Creates Original Articles From Your Content
La ressource originale : le texte de la revue en ligne Searchenginejournal : Google’s New Algorithm Creates Original Articles From Your Content Quelques outils de Text Mining
Quelques outils de Text Mining
- gate.ac.uk GATE
General Architecture for Text Engineering, solution de Text Mining. Gate est une suite d'outils Java initiée par l'université de Sheffield. C'est un produit Open Source. - sas.com Text Mining - SAS ® Text Miner
- Text Mining IBM Un brief explicatif du Text Mining, outils et techniques.
- statsoft.fr STATISTICA Text Miner de Statsoft
 Méthode pratique et concrète : Le lean pour tous, le Kaizen revisité, 10 étapes pour bâtir une gouvernance participative
Méthode pratique et concrète : Le lean pour tous, le Kaizen revisité, 10 étapes pour bâtir une gouvernance participative
 Instaurer la gouvernance démocratique dans l'entreprise
Instaurer la gouvernance démocratique dans l'entreprise
Avec exemple concret au sein d'une PME hitech
» Auteur : Alain Fernandez
» Pages : 360 pages
» ISBN : 978-2959320422
» Dispo : Format broché, Format Kindle,
Format epub
» Plus d'infos (extraits à télécharger...)
» Extrait sur google-livre
L’auteur
 Alain Fernandez est un spécialiste de la mesure de la performance, de l’aide à la décision et de la conception de tableaux de bord de pilotage. Au fil de ces vingt dernières années, il a conduit de nombreux projets de réalisation de système décisionnel en France et à l'International. Il est l'auteur de plusieurs livres publiés aux Éditions Eyrolles consacrés à ce thème, vendus à plusieurs dizaines de milliers d'exemplaires et régulièrement réédités.
Alain Fernandez est un spécialiste de la mesure de la performance, de l’aide à la décision et de la conception de tableaux de bord de pilotage. Au fil de ces vingt dernières années, il a conduit de nombreux projets de réalisation de système décisionnel en France et à l'International. Il est l'auteur de plusieurs livres publiés aux Éditions Eyrolles consacrés à ce thème, vendus à plusieurs dizaines de milliers d'exemplaires et régulièrement réédités. Ressources web
- Text Mining: An introduction to theory and some applications, Cambridge Assessment Network and Research
 À ce sujet, voir aussi
À ce sujet, voir aussi
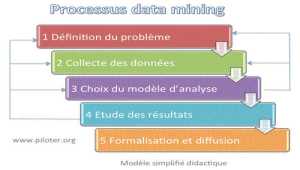 Data Mining, explorer les données du Data Warehouse
Data Mining, explorer les données du Data Warehouse
Il ne suffit pas de stocker une multitude de données au sein d'une base spécialisée, Data Warehouse ou Big Data, encore faut-il les exploiter. C'est là le rôle du Data Mining qui, bien utilisé, saura tirer les enseignements contenus dans cette masse de données bien trop importante pour se contenter des seuls outils statistiques. Voyons, le principe, les méthodes utilisées, les outils et un cas concret mettant en évidence l'importance de la qualité des données. OLAP On Line Analytical Processing
OLAP On Line Analytical Processing
Le modèle OLAP Online Analytical Processing est une solution technologique pour faciliter la manipulation de grandes quantités de données à des fins décisionnelles. En effet de part sa nature, cette base de données bien spécifique permet de réorganiser les informations à volonté afin de réaliser des analyses pointues. Voyons le principe. Qu'est-ce qu'un arbre de décision ?
Qu'est-ce qu'un arbre de décision ?
Qu'est ce qu'un arbre de decision ? Comment le bâtir, comment l'utiliser, quelles en sont les variantes ? Méthodes et outils d'analyse de la Business Intelligence. Analyse prédictive et réseau de neurones, définition
Analyse prédictive et réseau de neurones, définition
Analyse prédictive et réseau de neurones Méthodes et outils d'analyse de la Business Intelligence.
 À lire...
À lire...
Trois ouvrages pratiques pour s'initier au traitement de l'information textuelle, et ainsi mieux comprendre les principes du text mining et les enjeux de la Business Intelligence en langage naturel (Langue anglaise)...
 Text Mining With R: A Tidy Approach
Text Mining With R: A Tidy Approach
Julia Silge, David Robinson)
O'Reilly Media
192 pages
Dispo : www.amazon.fr
 Natural Language Processing with Python
Natural Language Processing with Python
Steven Bird, Ewan Klein, Edward Loper
O'Reilly Media
502 pages
Dispo : www.amazon.fr & Format Kindle
 Practical Text Analytics
Practical Text Analytics
Interpreting Text and Unstructured Data for Business Intelligence
Steven Struhl
Kogan Page
272 pages
Dispo : www.amazon.fr & Format Kindle
 Piloter l'Entreprise Innovante...
Piloter l'Entreprise Innovante...
La prise de décision en équipe ne s'improvise pas. Pour parvenir à ce mode de management délégataire, crucial pour les organisations actuelles, privées comme publiques, un indispensable travail de fond prélable est nécessaire. La méthode SOCRIDE centrée sur les questions incontournables de Confiance et de Reconnaissance est ici expliquée, illustrée et détaillée :
 Les tableaux de bord du manager innovant
Les tableaux de bord du manager innovant
Une démarche en 7 étapes pour faciliter la prise de décision en équipe
Alain Fernandez
Éditeur : Eyrolles
Pages : 320 pages
 Consultez la fiche technique »»»
Consultez la fiche technique »»»
Pour acheter ce livre :



Format ebook : PDF & ePub,
Format Kindle
Voir aussi...


 désigne l'ensemble des outils et techniques destinés à délivrer les informations pertinentes à chaque...")
 Partagez cet article...
Partagez cet article...





(total partages cumulés > 45)
Pour approfondir
Méthode pratique

Comment Décider en Équipe

Le Tableau de bord en mode "DIY"

Construire le système décisionnel de l'entreprise

Connaître les Bonnes Pratiques Projet

De Salarié à Entrepreneur
Méthode pratique

44 Astuces d'Entrepreneur



PDF Management 







Les plus lus...
 1. Qu'est-ce que le Big Data ? Définition et Principe
1. Qu'est-ce que le Big Data ? Définition et Principe2. Comment estimer la rentabilité du projet BI ?
3. Méthodes d'analyse statistiques de la Business Intelligence
