
Plus de 800 fiches pratiques pour les managers, sans pub et sans traceurs…

- ▶ Management de l'entreprise ▶ Management Démocratique
- Conception de la stratégie
- Principes de gouvernance
- La Performance des métier
- Le contrôle de gestion
- ▶ Innover en équipe
- L'Innovation et la Performance
- L'Innovation Managériale
- La Méthode SOCRIDE
- ▶ Décider au quotidien
- Le processus de Décision
- La Décision en équipe
- Les Techniques de décision
- ▶ Guide gratuit de l'Autoformation
- Méthode d'autoformation
- Les 7 Qualités pour réussir
- Comment s'auto-évaluer ?
- ▶ Formation Gratuite Management
- Formation tableau de bord et BI
- Formation Management de Projet
- Formation Entrepreneuriat
- ▶ ebook et PDF management gratuits
- ▶ PDF Entrepreneuriat
- ▶ ebook Perfonomique


 PDF
PDF

OLAP On Line Analytical Processing
Hyper Cube et Analyse Multidimensionnelle
 Les bases de données de type relationnel (SGBDR) sont inadaptées aux besoins
décisionnels.
Les bases de données de type relationnel (SGBDR) sont inadaptées aux besoins
décisionnels.Les requêtes décisionnelles, particulièrement complexes par principe, mobilisent abusivement les ressources machines. Lors de leur exécution, elles perturbent les traitements de production (OLTP).
De OLTP à OLAP
L'infocentre, base relationnelle exclusivement réservée aux requêtes décisionnelles, a pu durant un temps assez bref sembler proposer une solution. Mais les bases OLTP structurées en 2 dimensions ne se prêtent guère aux requêtes décisionnelles.
Les 18 règles du modèle OLAP
Les règles OLAP "Basic"
- 1. Multidimensional Conceptual View (règle 1)
- 2. Intuitive Data Manipulation (règle 10)
- 3. Accessibility (règle 3)
- 4. Batch Extraction vs Interpretive (nouvelle règle)
- 5. OLAP Analysis Models (nouvelle règle)
- 6. Client Server Architecture (anciennement règle 5)
- 7. Transparency (anciennement règle 2)
- 8. Multi-User Support (anciennement règle 8)
Les règles OLAP "Special"
- 9. Treatment of Non-Normalized Data (nouvelle règle)
- 10. Storing OLAP Results: Keeping Them Separate from Source Data (nouvelle règle)
- 11. Extraction of Missing Values (nouvelle règle)
- 12. Treatment of Missing Values (nouvelle règle)
Les règles OLAP "Reporting"
- 13. Flexible Reporting (anciennement règle 11)
- 14. Uniform Reporting Performance (anciennement règle 4)
- 15. Automatic Adjustment of Physical Level (remplace la règle 7)
Les règles OLAP "Dimension Control"
- 16. Generic Dimensionality (anciennement règle 6)
- 17. Unlimited Dimensions & Aggregation Levels (anciennement règle 12)
- 18. Unrestricted Cross-dimensional Operations (anciennement règle 9)
Langage MDX
Le langage MDX, né au sein des labos Microsoft (SQL Server OLAP), est un langage d'interrogation des bases multidimensionnelles plus adapté que le classique SQL pour le traitement des requêtes de type OLAP.MDX signifie "Multi-Dimensional Expressions".
Microsoft a proposé le langage MDX comme standard des interrogations multi dimensionnelles. Pour en savoir un peu plus, voir le tutoriel de Database Journal.
Les déclinaisons du concept OLAP
MOLAP ROLAP HOLAP et DOLAP
Techniquement, il existe deux modèles de stockage physique des données. Soit la base est structurellement multi-dimensionnelle, comme le propose le modèle MOLAP, soit la base est de type relationnel, mais utilisée comme une base multi-dimensionnelle comme le propose le modèle ROLAP. Rapidement, d'autres modèles spécifiques sont ensuite venus s'ajouter à ces deux concepts de base.
MOLAP
La base MOLAP (Multidimensional) est l'application physique du concept OLAP. Il s'agit réellement d'une structure multidimensionnelle. Les bases MOLAP sont rapides et performantes. Elles proposent des fonctionnalités particulièrement évoluées. Les bases de type MOLAP restent limitées au gigaoctet.
ROLAP
La base ROLAP (Relational) est en fait une classique base relationnelle organisée pour fonctionner comme une base OLAP. Les bases ROLAP sont bien plus lentes et nettement moins performantes que les bases MOLAP. Mais, immense avantage, elles sont sans limite de taille.
HOLAP
Un troisième modèle, le modèle HOLAP avec un H pour hybride, propose de cumuler les avantages des deux modèles précédents. Les données agrégées sont stockées sous formes multi-dimensionnelles, alors que les données détaillées sont stockées dans des structures relationnelles.
DOLAP
La base DOLAP (Desktop) est une base OLAP très limitée en taille, hébergée sur le poste client. Elle est bien entendu très rapide.
Quelques produits types
Tous les principaux éditeurs d'outils décisionnels intègrent un serveur Olap dans leur gamme : Microsoft Analysis Services, Oracle Express, Hyperion Essbase. Les offres évoluent régulièrement, changent de nom, se recomposent, il vaut mieux se référer régulièrement auprès des éditeurs.Essayer OLAP sans attendre
La meilleure façon de se familiariser avec le concept OLAP est encore de l'essayer "pour de vrai". C'est aujourd'hui possible, c'est très simple et peu coûteux. Excel ® et les tableaux dynamiques, les pivots tables sont bien pratiques pour une formation à la carte.5 étapes pour découvrir Olap
Suivez simplement les 5 étapes de la démarche suivante :- -1- Assurez-vous de disposer de suffisamment de place sur votre poste de travail (vérifiez la configuration requise).
- -2- Si ce n'est déjà fait, installez une version de Microsoft Excel relativement récente.
- -3- Rendez-vous sur le site : https://www.microsoft.com/fr-fr/sql-server/sql-server-downloads" target="_blank " >Microsoft ® SQL Server ® Express with Advanced Services, et téléchargez la version gratuite de SQL Server .
- -4- Achetez le livre :
 L'essentiel du tableau de bord
L'essentiel du tableau de bord
Un guide simple, pratique et concret pour concevoir et réaliser les tableaux de bord de l'entreprise
Alain Fernandez
Éditions Eyrolles
280 pages
Best seller francophone 5ème édition 2018
Pour acheter ce livre :


Format ebook : PDF & ePub, Kindle
Ce livre décrit toutes les étapes pour connecter et utiliser Excel avec le serveur OLAP de SQL server précédemment chargé. Vous apprendrez aussi à utiliser les tableaux dynamiques (pivots tables).
Téléchargez les exemples. - -5- Trouvez-vous un endroit au calme, et c'est tout !
Bon travail !
Mettre en oeuvre le cube OLAP
Une base OLAP ne se conçoit pas sans une réflexion de fond préalable fondée sur les habitudes et besoins réels des utilisateurs.En effet, il ne s'agit pas de chercher à sécuriser les "besoins futurs" en stockant un maximum de données et en multipliant le nombre de dimensions en partant du principe :
Actuellement, je ne sais pas pourquoi, mais peut-être que quelqu'un, un jour, en aura besoin.
Ce principe, à l'origine de bon nombre d'usines à gaz en informatique, est la meilleure garantie d'une explosion de la base.
3 erreurs de conception
Nigel Pendse, co-fondateur de "l'Olap Report", un site qui fut une référence incontournable de la Business Intelligence au cours de la première décennie de ce siècle et qui a disparu depuis, a bien analysé ces travers de conception particulièrement courants. Dans un texte fondateur de la technologie Olap, une référence pour tous les concepteurs, il décrit et illustre ces erreurs de conception selon 3 axes principaux de dérives :- 1) Stocker un maximum de données...pour autoriser tout type d'analyses
- 2) Définir un grand nombre de dimensions...pour faciliter les analyses
- 3) Multiplier les agrégats...pour améliorer les temps de réponse
À l'usage, on constate que la majorité des requêtes ne portent généralement que sur un ensemble réduit de données. De surcroît, les analyses exotiques, si elles sont lancées lors des premiers jours d'utilisation pour tester la machine, restent plutôt exceptionnelles en usage courant.
C'est par cette identification que doit commencer l'étude de conception d'un cube OLAP.
Ce texte, écrit avant l'essor du Big Data (voir ici le dossier dédié), ne perd pas pour autant sa pertinence. La construction de modèle utilisable dans l'aide à la décision est d'une autre ampleur.
Les dérives du cube OLAP
L’expansion non maîtrisée constitue le principal problème des systèmes OLAP. La tendance naturelle conduit à 3 erreurs de conception comme :- Essayer de stocker le maximum de données
- Définir de trop nombreuses dimensions
- Rechercher le meilleur temps de réponse
Stocker un maximum de données
Les utilisateurs auront besoin de rapprocher de nombreuses données et de conserver un maximum d’historiques. Actuellement, avec un rythme de renouvellement accéléré des gammes de produits des entreprises, les données évoluent très rapidement et demandent des bases de plus en plus volumineuses.Définir de nombreuses dimensions
Les dimensions doivent être prévues à l’origine du chargement de la base Olap. Pour éviter des impasses et faciliter les analyses, les utilisateurs ont tendance à définir de nombreuses dimensions pour un même ensemble de données. Souvent ces dimensions restent inexploitées et occupent une place inutile. À l’analyse des bases existantes, on constate qu’elles contiennent de nombreuses cases vides et les données sont très clairsemées.
(La modélisation Big Data est un tout autre sujet...)
Rechercher le meilleur temps de réponse
Pour être acceptable, un maximum de requêtes doivent être traitées en moins de 5 secondes. Quelques unes uniquement seront traitées en un temps maximal de 30 secondes. Au delà, c’est le domaine de l’inacceptable.Pour un maximum de performance, de nombreux agrégats sont pré-calculés et stockés. Et, paradoxe, quelquefois le nombre d’agrégats stockés dépasse le nombre de données initiales.
En résultat, les bases sont rapidement saturées et peu utilisables.
En complément pour des requêtes accélérées voir le In-Memory.
À la base, une erreur de raisonnement
L’approche initiale des bases OLAP est dans le même esprit que les premiers Data warehouse, et part du principe que pour une plus grande efficacité, il suffit de mettre à la disposition des décideurs le maximum de données. Ces derniers auront ainsi, selon ce principe, toute liberté pour effectuer tous les croisements qui leur sembleraient opportuns.Ce raisonnement n’est plus possible et les systèmes conçus selon ce principe sont un échec. Les données doivent être structurées « intelligemment » dans les bases, en connaissance et avec compréhension des besoins réels des utilisateurs.
Une conception réfléchie
Nous ne bâtirons pas une architecture technologique extravagante en supposant qu’un décideur potentiel pourrait éprouver le désir de rapprocher des données totalement antinomiques.Un jour, je posais la question à un prosélyte de ce type d’architecture. Je lui ai demandé quel pouvait être l’intérêt pour un décideur de terrain, de comparer les caractéristiques intrinsèques de la production d’une référence X, avec le résultat des ventes du mois dernier dans la zone Europe du Sud. Il m’avait répondu : « Personnellement je ne le sais pas, mais je ne peux pas empêcher un décideur d’effectuer ce rapprochement s’il le souhaite. Il en tirera peut-être un enseignement et prendra LA décision pertinente. ».
À première vue, l’argument semble de poids. Pourtant, c’est en cultivant le mythe de l’information « miracle » et cachée que l’on bâtit les « usines à gaz » peu performantes et peu adaptées pour l’usage courant du décideur en situation.
Avant de faire des recoupements tous azimuts, le décideur à besoin de réponses à des problèmes précis. Il est vrai qu’il aura tout intérêt à ne pas rester cantonné dans sa sphère, et rien ne l’empêche de souhaiter rapprocher des informations qui, a priori, ne sont en rien concomitantes.
Nous remplaçons à escient le terme données par information. Comme nous l’avons vu à l’étape 7 de la méthode Gimsi, l’enseignement sera beaucoup plus profitable en échangeant avec le professionnel concerné une information construite et structurée, plutôt que de chercher à analyser des données externes à notre périmètre d’activité et donc peu porteuses de sens.
Ce texte a été écrit il y a déjà quelques années. Il est toutefois bon de noter que le Big Data, non pas en théorie mais en pratique, n'a rien changé à ce raisonnement (voir notamment les limites du Big Data).
Solution Olap Open Source
- Mondrian, projet Pentaho
- Voir le projet Data Warehouse Open Source.
Quelques fournisseurs
- Oracle Essbase Olap
- IBM Olap Tools (Cognos)
- SAP BusinessObjects Voyager
- Voir aussi les "pivots tables" ou tableaux
croisés dynamiques de Microsoft Excel
Solution Olap Open Source
- Mondrian, projet Pentaho
- Voir le projet Data Warehouse Open Source
 Méthode pratique et concrète : Le lean pour tous, le Kaizen revisité, 10 étapes pour bâtir une gouvernance participative
Méthode pratique et concrète : Le lean pour tous, le Kaizen revisité, 10 étapes pour bâtir une gouvernance participative
 Instaurer la gouvernance démocratique dans l'entreprise
Instaurer la gouvernance démocratique dans l'entreprise
Avec exemple concret au sein d'une PME hitech
» Auteur : Alain Fernandez
» Pages : 360 pages
» ISBN : 978-2959320422
» Dispo : Format broché, Format Kindle,
Format epub
» Plus d'infos (extraits à télécharger...)
» Extrait sur google-livre
L’auteur
 Alain Fernandez est un spécialiste de la mesure de la performance, de l’aide à la décision et de la conception de tableaux de bord de pilotage. Au fil de ces vingt dernières années, il a conduit de nombreux projets de réalisation de système décisionnel en France et à l'International. Il est l'auteur de plusieurs livres publiés aux Éditions Eyrolles consacrés à ce thème, vendus à plusieurs dizaines de milliers d'exemplaires et régulièrement réédités.
Alain Fernandez est un spécialiste de la mesure de la performance, de l’aide à la décision et de la conception de tableaux de bord de pilotage. Au fil de ces vingt dernières années, il a conduit de nombreux projets de réalisation de système décisionnel en France et à l'International. Il est l'auteur de plusieurs livres publiés aux Éditions Eyrolles consacrés à ce thème, vendus à plusieurs dizaines de milliers d'exemplaires et régulièrement réédités. À ce sujet, voir aussi
À ce sujet, voir aussi
 Data Warehouse et OLAP Open Source
Data Warehouse et OLAP Open Source
Panorama des solutions Data Warehouse et OLAP Open source : la Business Intelligence et le progiciel libre... Qu'est-ce qu'un arbre de décision ?
Qu'est-ce qu'un arbre de décision ?
Qu'est ce qu'un arbre de decision ? Comment le bâtir, comment l'utiliser, quelles en sont les variantes ? Méthodes et outils d'analyse de la Business Intelligence.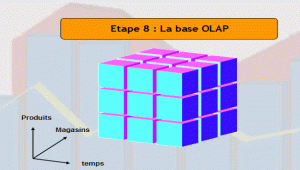 Formation les analyses multidimensionnelles OLAP
Formation les analyses multidimensionnelles OLAP
Formation en ligne : Équipez votre tableau de bord d'un cube OLAP pour les analyses multidimensionnelles...
 À lire...
À lire...
Les principes de Olap expliqués. Exemples pratiques avec Oracle Essbase. Comment conduire le projet, bâtir la base multidimensionnelle. Techniques, conseils et recommandations pour configurer et optimiser la base...
 Oracle Essbase & Oracle OLAP
Oracle Essbase & Oracle OLAP
The Guide to Oracle's Multidimensional Solution
Michael Schrader
McGraw-Hill Osborne Media
524 pages (anglais)
Dispo : www.amazon.fr & Format Kindle
Livres de référence du site
 Les nouveaux tableaux de bord des managers
Les nouveaux tableaux de bord des managers
Le projet Business Intelligence clés en main
Alain Fernandez
6ème édition Eyrolles
468 pages
Pour acheter ce livre :
Format ebook : PDF ou ePub, Kindle
L'essentiel du tableau de bord
Méthode complète et mise en pratique avec Microsoft Excel
Alain Fernandez
5ème édition Eyrolles
280 pages
Pour acheter ce livre :
Format ebook : PDF & ePub, Kindle
 Piloter l'Entreprise Innovante...
Piloter l'Entreprise Innovante...
Avez-vous déjà essayé d'instaurer la prise de décision en équipe ? Sans précautions préalables, rapidement, le consensus le plus mou qui soit vient casser les plus pures ambitions. Mais connaissez-vous la méthode SOCRIDE centrée sur les questions incontournables de Confiance et de Reconnaissance ? Rien de plus facile ! Elle est expliquée, illustrée et détaillée dans ce livre :
 Les tableaux de bord du manager innovant
Les tableaux de bord du manager innovant
Une démarche en 7 étapes pour faciliter la prise de décision en équipe
Alain Fernandez
Éditeur : Eyrolles
Pages : 320 pages
 Consultez la fiche technique »»»
Consultez la fiche technique »»»
Pour acheter ce livre :
Format ebook : PDF & ePub,
Format Kindle
Voir aussi...


 désigne l'ensemble des outils et techniques destinés à délivrer les informations pertinentes à chaque...")
 Partagez cet article...
Partagez cet article...





(total partages cumulés > 85)
Pour approfondir
Méthode pratique

Comment Décider en Équipe

Le Tableau de bord en mode "DIY"
Construire le système décisionnel de l'entreprise
Connaître les Bonnes Pratiques Projet

De Salarié à Entrepreneur
Méthode pratique

44 Astuces d'Entrepreneur



PDF Management 







Les plus lus...
 1. Qu'est-ce que le Big Data ? Définition et Principe
1. Qu'est-ce que le Big Data ? Définition et Principe2. Comment estimer la rentabilité du projet BI ?
3. Méthodes d'analyse statistiques de la Business Intelligence
